
Contents of Volume 15 (2005)
5/2005 4/2005 3/2005 2/2005 1/20056/2005
- [1] Dikkers H., Rothkrantz L. (Netherlands): Support vector machines in ordinal classification: an application to corporate credit scoring, 491-507.
Risk assessment of credit portfolios is of pivotal importance in the banking industry. The bank that has the most accurate view of its credit risk will be the most profitable. One of the main pillars in the assessing credit risk is the estimated probability of default of each counterparty, ie the probability that a counterparty cannot meet its payment obligations in the horizon of one year. A credit rating system takes several characteristics of a counterparty as inputs and assigns this counterparty to a rating class. In essence, this system is a classifier whose classes lie on an ordinal scale.
In this paper we apply linear regression ordinal logistic regression, and support vector machine techniques to the credit rating problem. The latter technique is a relatively new machine learning technique that was originally designed for the two-class problem. We propose two new techniques that incorporate the ordinal character of the credit rating problem into support vector machines. The results of our newly introduced techniques are promising.
- [2] Dunis C. L., Laws J., Evans B. (United Kingdom): Modelling with recurrent and higher order networks: A comparative analysis, 509-523.
This paper investigates the use of Higher Order Neural Networks using a number of architectures to forecast the Gasoline Crack spread. The architectures used are Recurrent Neural Network and Higher Order Neural Networks; these are benchmarked against the standard MLP model. The final models are judged in terms of out-of-sample annualised return and drawdown, with and without a number of trading filters.
The results show that the best model of the spread is the recurrent network with the largest out-of-sample returns before transactions costs, indicating a superior ability to forecast the change in the spread. Further the best trading model of the spread is the Higher Order Neural Network with the threshold filter due a superior in- and out-of-sample risk/return profile.
- [3] Xiaoping Lai, Bin Li (China): An efficient learning algorithm generating small RBF neural networks, 525-533.
This paper presents an efficient learning algorithm that generates radial basis function neural network with few neurons. The neural network adds neurons according to a growth criterion defined by the current output error, the current input's distance to the nearest center, and the root-mean-square output error over a sliding windows, deletes neurons by a pruning strategy based on the error reduction rates, and updates the output-layer weights with a Givens QR decomposition based on the orthogonalized least square algorithm. Simulations on two benchmark problems demonstrate that the algorithm produces smaller networks than RAN, RANEKF, and MRAN, and consumes less training time than RAN, RANEKF, MRAN, and GAP-RBF.
- [4] Majerová D., Kukal J. (Czech Republic): Łukasiewicz ANN for local image processing, 535-551.
One of the useful areas of the 2D image processing is called de-noising. When both original (ideal) and noisy images are available, the quality of de-noising is measurable. Our paper is focused to local 2D image processing using £ukasiewicz algebra with the square root function. The basic operators and functions in given algebra are first defined and then analyzed. The first result of the fuzzy logic function (FLF) analysis is its decomposition and realization as £ukasiewicz network (£N) with three types of processing nodes. The second result of FLF decomposition is the decomposed £ukasiewicz network (D£N) with dyadic preprocessing and two types of processing nodes. The decomposition chain, which begins with FLF and converts it to £N and then to D£N, terminates as £ukasiewicz artificial neural network (\lann) with dyadic preprocessing and only one type of processing node. Then the £ANN is able to learn its integer weights in the ANN style. We are able to realize a set of individual FLF filters as £ANN. Their preprocessing strategies are based on the pixel neighborhood, sorted list, Walsh list, and L-estimates. The quality of de-noising can be improved via compromise filtering. Two types of compromise de-noising filters are also realizable as £ANN. One of them is called constrained referential neural network (CRNN). The other one is called dyadic weight neural network (DWNN). The compromise filters operate with the values from the set of individual filters. Both CRNN and DWNN are able to increase the quality of image processing as demonstrated on the biomedical MR image. All the calculations are realized in the Matlab environment.
- [5] Ondráček T. (Czech Republic): Constructive gradient neural network, 553-566.
The paper deals with a description of a constructive neural network based on gradient initial setting of its weights. The network has been used as a pattern classifier of two dimensional patterns but it can be generally used to n x m associative problems. A network topology, processes of learning and retrieving, experiments and comparison to other neural networks are described.
- [6] Svítek M., Novovičová J. (Czech Republic): Performance parameters definition and processing, 567-577.
The definition of the performance parameters, especially accuracy, reliability, dependability are presented. Their estimations are developed by using results from the theory of statistical tolerance intervals in the case of random sample from a normal distribution. The proposed approach is illustrated on two examples.
- [7] Zhang Q., Wei X., Xu J. (China): Global asymptotic stability of cellular neural networks with infinite delay, 579-589.
Global asymptotic stability of cellular neural networks with infinite delay is considered in this paper. Based on the Lyapunov stability theorem combing with modified Young inequality, some new sufficient conditions are given for global asymptotic stability of equilibrium point of cellular neural networks with infinite delay. The results are less conservative than that established in the earlier references. Two examples are presented to illustrate the applicability of these conditions.
- [8] Contents volume 15 (2005), 591-593.
- [9] Author's index volume 15 (2005), 595-597.
5/2005
- [1] Spišiak M., Kozák Š. (Slovakia): Automatic generation of neural network structures using genetic algorithm, 381-394.
This paper deals with a generalized automatic method used for designing artificial neural network (ANN) structures. One of the most important problems is designing the optimal ANN for many real applications. In this paper, two techniques for automatic finding an optimal ANN structure are proposed. They can be applied in real-time applications as well as in fast nonlinear processes. Both techniques proposed in this paper use the genetic algorithms (GA). The first proposed method deals with designing a structure with one hidden layer. The optimal structure has been verified on a nonlinear model of an isothermal reactor. The second algorithm allows designing ANN with an unlimited number of hidden layers each of which containing one neuron. This structure has been verified on a highly nonlinear model of a polymerization reactor. The obtained results have been compared with the results yielded by a fully connected ANN.
- [2] Húsek D., Snášel V., Owais S. S. J., Krömer P. (Czech Republic): Boolean Queries Optimization by Genetic Programming, 395-409.
Information retrieval systems depend on Boolean queries. Proposed evolution of Boolean queries should increase the performance of the information retrieval system. Information retrieval systems quality are measured in terms of two different criteria, precision and recall. Evolutionary techniques are widely applied for optimization tasks in different areas including the area of information retrieval systems. In information retrieval applications both criteria have been combined in a single scalar fitness function by means of a weighting scheme 'harmonic mean'. Usage of genetic algorithms in the Information retrieval, especially in optimizing a Boolean query, is presented in this paper. Influence of both criteria, precision and recall, on quality improvement are discussed as well.
- [3] Musilek P. (Canada): Assessing empirical software data with MLP neural networks, 411-423.
Software measurements provide developers and software managers with information on various aspects of software systems, such as effectiveness, functionality, maintainability, or the effort and cost needed to develop a software system. Based on collected data, models capturing some aspects of software development process can be constructed. A good model should allow software professionals to not only evaluate current or completed projects but also predict future projects with an acceptable degree of accuracy.
Artificial neural networks employ a parallel distributed processing paradigm for learning of system and data behavior. Some network models, such as multilayer perceptrons, can be used to build models with universal approximation capabilities. This paper describes an application in which neural networks are used to capture the behavior of several sets of software development related data. The goal of the experiment is to gain an insight into the modeling of software data, and to evaluate the quality of available data sets and some existing conventional models.
- [4] Pelikan E., Simunek M. (Czech Republic): Risk management of the natural gas consumption using genetic algorithms, 425-436.
There is no need to emphasize strongly the economical aspect of energy consumption forecasting in the current conditions of price formation for natural gas distribution companies. Knowledge of the future maximal values of a natural gas load over a day, a week or a month prediction horizon is very important for dispatchers in power distribution companies, who use this information for operating and planning. In our contribution we discuss a possibility to connect the natural gas consumption prediction module with a risk management module. The distribution function of the prediction errors (coming from the prediction module) is estimated and probability P (load > threshold) is derived. The optimal selection of possible regulations of individual consumers is performed by maximizing the economical profit or minimizing the company loss. The number of a possible combination is very large and therefore we use genetic algorithms (GA) as a powerful tool. The results from the two examples are shown: the optimal regulation design strategy (minimal loss) and the optimal gas selling strategy design (maximal profit).
- [5] Lindemann A., Dunis C. L., Lisboa P. (United Kingdom): Probability distribution architectures for trading silver, 437-470.
The purpose of this paper is twofold. Firstly, to investigate the merit of estimating probability density functions rather than level or classification estimations on a one-day-ahead forecasting the task of the silver time series.
This is done by benchmarking the Gaussian mixture neural network model (as a probability distribution predictor) against two other neural network designs representing a level estimator (the Mulit-layer perceptron network [MLP]) and a classification model (Softmax cross entropy network model [SCE]). In addition, we also benchmark the results against standard forecasting models, namely a naive model, an autoregressive moving average model (ARMA) and a logistic regression model (LOGIT).
The second purpose of this paper is to examine the possibilities of improving the trading performance of those models by applying confirmation filters and leverage.
As it turns out, the three neural network models perform equally well generating a recognisable gain while ARMA benchmark model, on the other hand, seems to have picked up the right rhythm of mean reversion in the silver time series, leading to very good results. Only when using more sophisticated trading strategies and leverage, the neural network models show an ability to identify successfully trades with a high Sharpe ratio and outperform the ARMA model.
- [6] Trebatický P. (Slovakia): Recurrent Neural Network Training with the Kalman Filter-based Techniques, 471-488.
Recurrent neural networks, in contrast to the classical feedforward neural networks, handle better the inputs that have space-time structure, e.g. symbolic time series. Since the classic gradient methods for recurrent neural network training on longer input sequences converge very poorly and slowly, alternative approaches are needed. We describe the training method with the Extended Kalman Filter and with its modifications Unscented Kalman Filter, nprKF and with their joint versions. The Joint Unscented Kalman Filter was not used for this purpose before. We compare the performance of these filters and of the classic Truncated Backpropagation Through Time (BPTT(h)) in two experiments for next-symbol prediction - word sequence generated by Reber automaton and the sequence generated by quantising the activations of a laser in a chaotic regime. All the new filters achieved significantly better results.
- [7] Book review, 489-490.
4/2005
- [1] Editorial, 281.
- [2] Antoch J. (Czech Republic): Visual data mining of large data sets using Vitamin-S system, 283-293.
Never before in history data has been generated at such high volumes as it is today. It is estimated that every year about 1 Exabyte (= 1 Million Terabyte) of data are generated, of which a large portion is available in digital form. Exploring and analyzing the vast volumes of data becomes increasingly difficult. This paper describes system Vitamin-S that aims to help when analyzing very large data sets.
- [3] Bartkowiak A. (Poland): Distal points viewed in Kohonen's self-organizing maps, 295-302.
Kohonen's self-organizing maps are a recognized tool for finding representative data vectors and clustering the data. To what extent is it possible to preserve the topology of the data in the constructed planar map? We address the question looking at distal data points located at the peripherals of the data cloud and their position in the provided map. Several data sets have been investigated; we present the results for two of them: the Glass data (dimension d=7) and the Ionosphere data (dimension d=32). It was found that the distal points are reproduced either at the edges (borders) of the map, or at the peripherals of dark regions visualized in the maps.
- [4] Di Zio M., Sacco G., Scanu M., Vicard P. (Italy): Multivariate techniques for imputation based on Bayesian networks, 303-309.
In this paper, we compare two imputation procedures based on Bayesian networks. One method imputes missing items of a variable taking advantage only on information of its parents, while the other takes advantage of its Markov blanket. The structure of the paper is as follows. The first section contains an illustration of Bayesian networks. Then, we explain how to use the information contained in Bayesian networks in Section 2. In Section 3, we describe two evaluation indicators of imputation procedures. Finally, a Monte Carlo evaluation is carried on a real data set in Section 4.
- [5] Gelnarová E., Šafařík L. (Czech Republic): Comparison of three statistical classifiers on a prostate cancer data, 311-318.
Introduction: The dataset of 826 patients who were suspected of the prostate cancer was examined. The best single marker and the combination of markers which could predict the prostate cancer in very early stage of the disease were looked for. Methods: For combination of markers the logistic regression, the multilayer perceptron neural network and the k-nearest neighbour method were used. 10 models for each method were developed on the training data set and the predictive accuracy verified on the test data set. Results and conclusions: The ROCs for the models were constructed and AUCs were estimated. All three examined methods have given comparable results. The medians of estimates of AUCs were 0.775, which were larger than AUC of the best single marker.
- [6] Gibert K., Nonell R., Velarde J. M., Colillas M. M. (Spain): Knowledge Discovery with Clustering: Impact of metrics and reporting phase by using KLASS, 319-326.
One of the features involved in clustering is the evaluation of distances between individuals. This paper is related with the use of different mixed metrics for clustering messy data. Indeed, in real complex domains it becomes natural to deal with both numerical and symbolic attributes. This can be treated on different approaches. Here, the use of mixed metrics is followed. In the paper, impact of metrics on final classes is studied. The application relates to clustering municipalities of the metropolitan area of Barcelona on the bases of their constructive behavior, the number of buildings of different types being constructed, or the politics orientation of the local government. Importance of the reporting phase is also faced in this work. Both clustering with several distances and the interpretation oriented tools are provided by a software specially designed to support Knowledge Discovery on real complex domains, called KLASS.
- [7] Giordano F., La Rocca M., Perna C. (Italy): Neural network sieve bootstrap for nonlinear time series, 327-334.
In this paper a sieve bootstrap scheme, the Neural Network Sieve bootstrap, for nonlinear time series is proposed. The approach, which is non parametric in its spirit, does not have the problems of other nonparametric bootstrap techniques such as the blockwise schemes. The procedure performs similarly to the AR-Sieve bootstrap for linear processes while it outperforms the AR-Sieve and the moving block bootstrap for nonlinear processes, both in terms of bias and variability.
- [8] Hennig C. (Germany): Classification and outlier identification for the GAIA mission, 335-342.
The GAIA satellite is scheduled for launch in 2010. GAIA will observe spectral data of about 1 billion celestial objects. Part of the preparation of the GAIA mission is the choice of an efficient classification method to classify the observed objects automatically as stars, double stars, quasars or other objects. For this reason, there have been two blind testing experiments on simulated data. In this paper, the blind testing procedure is described as well as the results of a cross-validation experiment to choose a good classifier from a broad class of methods, comprising, e.g., the support vector machine, neural networks, nearest neighbor methods, classification trees and random forests. Because of a lack of information about their nature, no outliers ("other objects"-class) have been simulated. A new strategy to identify outliers based on only "clean" training data independent of the chosen classification method is proposed.
- [9] Kuroda M. (Japan): Data Augmentation algorithm for graphical models with missing data, 343-350.
In this paper, we discuss an efficient Bayesian computational method when observed data are incomplete in discrete graphical models. The data augmentation (DA) algorithm of Tanner and Wong [8] is applied to finding the posterior distribution. Utilizing the idea of local computation, it is possible to improve the DA algorithm. We propose a local computation DA (LC-DA) algorithm and evaluate its computational efficiency.
- [10] Lipinski P. (Poland, France): Clustering of large number of stock market trading rules, 351-357.
This paper addresses the problem of clustering in large sets discussed in the context of financial time series. The goal is to divide stock market trading rules into several classes so that all the trading rules within the same class lead to similar trading decisions in the same stock market conditions. It is achieved using Kohonen self-organizing maps and the K-means algorithm. Several validity indices are used to validate and assess the clustering. Experiments were carried out on 350 stock market trading rules observed over a period of 1300 time instants.
- [11] Michalak K., Lipinski P. (Poland, France): Prediction of high increases in stock prices using neural networks, 359-366.
This paper addresses the problem of stock market data prediction. It discusses the abilities of neural networks to learn and to forecast price quotations as well as proposes a neural approach to the future stock price prediction and detection of high increases or high decreases in stock prices. In order to validate the approach, a large number of experiments were performed on real-life data from the Warsaw Stock Exchange.
- [12] Shimamura T., Masahiro M. (Japan): Flexible regression modeling via radial basis function networks and lasso-type estimator, 367-374.
Radial basis function networks provides a more flexible model and gives a very good performance over a wide range of applications. However, in the modeling process, care is taken not to choose the number of the basis functions and the positions of the centres, the regularization parameter and the smoothing parameter as appropriate according to the model complexity, they often gives poor generalization performance.
In this paper, we develop a new model building procedure based on radial basis function networks; positioning the centres with k-means clustering for the conditional distribution Pr(x|y) and estimating the weights by maximum penalized likelihood with Lasso penalty. We present an information criterion for choosing the regularization and smoothing parameters in the models. The proposed procedure determines the proper number and location of the centres automatically. The simulation result shows that the proposed method performs very well.
- [13] Sohn S. Y, Shin H. W. (Korea): EWMA combination of both GARCH and neural networks for the prediction of exchange rate, 375-380.
Exchange rate forecasting is an important and challenging task for both academic researchers and business practitioners. Several statistical or artificial intelligence approaches have been applied to forecasting exchange rate. The recent trend to improve the prediction accuracy is to combine individual forecasts in the form of the simple average or weighted average where the weight reflects the inverse of the prediction error. This kind of combination, however, does not reflect the current prediction error more than the relatively old performance. In this paper, we propose a new approach where the forecasting results of GARCH and neural networks are combined based on the weight reflecting the inverse of EWMA of the mean absolute percentage error (MAPE) of each individual prediction model. Empirical study results indicate that the proposed combining method has better accuracy than GARCH, neural networks, and traditional combining methods that utilize the MAPE for the weight.
3/2005
- [1] Editorial, 187.
- [2] Gecow A. (Poland): From a "fossil" problem of recapitulation existence to computer simulation and answer, 189-201.
Modern biology usually rejects the concept of recapitulation of phylogeny in ontogeny as describing a non-existent phenomenon and regards it as a "case closed". The minority of biologists (mainly paleontologists and older evolutionists) that recognize the phenomenon in their empirical observations, cannot provide a viable mechanism for it, except for referring to Darwin's and Schmalhasen's intuitions, lacking rigorous quantitative testability. Now a possibility arises to check this hypothesis and this is the theme of this paper. The paper presents an abstract model of complex system adaptive evolution and results of its computer simulations. The system is described as direct network similar to Kauffman's Boolean network. The model indicates that the "recapitulation" is a statistical phenomenon expected as a result of long adaptive evolution of a complex system and is a very good quantitative first approximation of evolutionary phenomena. The simulation successfully replicated the similarities of functional and historical sequence and other main regularities: Naef's "terminal modification and conservation of early stages" and Weismann's "terminal addition" as terminal predominance of addition over removal. These tendencies are observed upon reaching certain complexity threshold. Thus, now it will be a problem requiring explanation if we do not observe statistical recapitulation in a more complex ontogeny.
- [3] Lee R. (United Kingdom): Engineering neural models of cognitive planning, emotion and volition, 203-214.
In his paper, Aleksander proposed five axioms for the presence of minimal consciousness in an agent. The last two of these were planning and affective evaluation of plans, respectively. The first three axioms - depiction, imagination and attention - have already been implemented in neural models in the laboratory at Imperial College. The present paper describes efforts to model the last two axioms in a similar manner, i.e., through digital neuromodelling.
- [4] Graham R., Dawson M. R. W. (USA): Using artificial neural networks to examine event-related potentials of face memory, 215-227.
The N250r is a face-sensitive event-related potential (ERP) deflection whose long-term memory sensitivity remains uncertain. We investigated the possibility that long-term memory-related voltage changes are represented in the early ERP's to faces but methodological considerations could affect how these changes appear to be manifested. We examined the effects of two peak analysis procedures in the assessment of the memory-sensitivity of the N250r elicited in an old/new recognition paradigm using analysis of variance (ANOVA) and artificial neural networks (ANN's). When latency was kept constant within subjects, ANOVA was unable to detect differences between ERP's to remembered and new faces; however, an ANN was. Network interpretation suggested that the ANN was detecting amplitude differences at occipitotemporal and frontocentral sites corresponding to the N250r. When peak latency was taken into account, ANOVA detected a significant decrease in onset latency of the N250r to remembered faces and amplitude differences were not detectable, even with an ANN. Results suggest that the N250r is sensitive to long-term memory. This effect may be a priming phenomenon that is attenuated at long lags between faces. Choice of peak analysis procedures is critical to the interpretation of phasic memory effects in ERP data.
- [5] Cervantes A., Galván I., Isasi P. (Spain): Binary particle swarm optimization in classification, 229-241.
Purpose of this work is to show that the Particle Swarm Optimization Algorithm may improve the results of some well known Machine Learning methods in the resolution of discrete classification problems. A binary version of the PSO algorithm is used to obtain a set of logic rules that map binary masks (that represent the attribute values), to the available classes. This algorithm has been tested both in a single pass mode and in an iterated mode on a well-known set of problems, called the MONKS set, to compare the PSO results against the results reported for that domain by the application of some common Machine Learning algorithms.
- [6] Mirzayans T., Parimi N., Pilarski P., Backhouse C., Wyard-Scott L., Musilek P. (Canada): A swarm-based system for object recognition, 243-255.
Swarm intelligence is an emerging field with wide-reaching application opportunities in problems of optimization, analysis and machine learning. While swarm systems have proved very effective when applied to a variety of problems, swarm-based methods for computer vision have received little attention. This paper proposes a swarm system capable of extracting and exploiting the geometric properties of objects in images for fast and accurate recognition. In this approach, computational agents move over an image and affix themselves to relevant features, such as edges and corners. The resulting feature profile is then processed by a classification subsystem to categorize the object. The system has been tested with images containing several simple geometric shapes at a variety of noise levels, and evaluated based upon the accuracy of the system's predictions. The swarm system is able to accurately classify shapes even with high image noise levels, proving this approach to object recognition to be robust and reliable.
- [7] Pizzi N. J. (Canada): Classification of biomedical spectra using stochastic feature selection, 257-268.
When dealing with the curse of dimensionality (small sample size with many dimensions), feature selection is an important preprocessing strategy for the analysis of biomedical data. This issue is particularly germane to the classification of high-dimensional class-labeled biomedical spectra as is often acquired from magnetic resonance and infrared spectrometers. A technique is presented that stochastically selects feature subsets with varying cardinality for automated discrimination using two types of neural network classifiers. The results are benchmarked against classifiers using the entire feature set with and without averaging. Stochastic feature subset selection had significantly fewer misclassifications than either of the benchmarks.
- [8] Mukherjee S., Mitra S. (India): Fuzzy measures in Hidden Markov Models, 269-280.
Recently Hidden Markov Models (HMMs) and Stochastic grammar models have been extensively employed in various fields like computational biology, speech recognition, gesture recognition and text processing with the problems being modelled using classical probability measures. Fuzzy measure is an extension to the classical measure theory with promising applications in various areas. Some generalized HMMs have been developed with fuzzy measures for the speech recognition problem. The well known algorithms used for HMMs are thereby shown to execute faster. In this article, we discuss the classical and fuzzy measure formulation of HMMs, followed by applications in speech recognition using fuzzy measures. We also indicate the possible scope for their application to Bioinformatics.
2/2005
- [1] Kramosil I. (Czech Republic): Possibilistic measures and possibly favorable elementary random events, 85-109.
Elementary random events possibly favorable to a random event are defined as those elementary random events for which we are not able to prove or deduce, within the limited framework of a decision procedure being at our disposal, that they are not favorable to the random event in question. Under some conditions, probabilities of the sets of possibly favorable elementary random events induce uniquely a possibilistic measure on the system of all subsets of the universe of elementary random events under consideration. Moreover, each possibilistic measure defined on this power-set can be obtained, or at least approximated to the degree of precision a priori given, in this way. Some results concerning the combinations of decision systems and decision systems induced by random variables are introduced and proved.
- [2] Lim W. S., Rao M. V. C. (Malaysia): Stabilization of Sequential Learning Neural Network in Sonar Target Classification via a Novel Approach, 111-127.
In this paper, the processing of sonar signals has been carried out using a Minimal Resource Allocation Network (MRAN) in identification of commonly encountered features in indoor environments. The stability-plasticity behaviors of the network have been investigated. From previous observations, the experimental results show that MRAN possesses lower network complexity but experiences higher plasticity, and is unstable. A novel approach is proposed to solve these problems in MRAN and has also been experimentally proven that the network generalizes faster at a lower number of neurons (nodes) compared to the original MRAN. This new approach has been applied as a preprocessing tool to equip the network with certain information about the data to be used in training the network later. With this initial "guidance", the network predicts extremely well in both sequential and random learning.
- [3] Serpen G. (USA): A Heuristic and Its Mathematical Analogue within Artificial Neural Network Adaptation Context, 129-136.
This paper presents an observation on adaptation of Hopfield neural network dynamics configured as a relaxation-based search algorithm for static optimization. More specifically, two adaptation rules, one heuristically formulated and the second being gradient descent based, for updating constraint weighting coefficients of Hopfield neural network dynamics are discussed. Application of two adaptation rules for constraint weighting coefficients is shown to lead to an identical form for update equations. This finding suggests that the heuristically-formulated rule and the gradient descent based rule are analogues of each other. Accordingly, in the current context, common sense reasoning by a domain expert appears to possess a corresponding mathematical framework.
- [4] Ding Gang, Zhong Shisheng (China): Time series prediction by parallel feedforward process neural network with time-varied input and output, 137-147.
Time series prediction plays an important role in engineering applications. Artificial neural networks seem to be a useful tool to solve these problems. However, in real engineering, the inputs and outputs of many complicated systems are time-varied functions. Conventional artificial neural networks are not suitable to predicting time series in these systems directly. In order to overcome this limitation, a parallel feedforward process neural network (PFPNN) is proposed. The inputs and outputs of the PFPNN are time-varied functions, which makes it possible to predict time series directly. A corresponding learning algorithm for the PFPNN is developed. To simplify this learning algorithm, appropriate orthogonal basis functions are selected to expand the input functions, output functions and network weight functions. The effectiveness of the PFPNN and its learning algorithm is proved by the Mackey-Glass time series prediction. Finally, the PFPNN is utilized to predict exhaust gas temperature time series in aircraft engine condition monitoring, and the simulation test results also indicate that the PFPNN has a faster convergence speed and higher accuracy than the same scale multilayer feedforward process neural network.
- [5] Bouchner P., Hajný M., Novotný M., Piekník R., Sojka J. (Czech Republic): Car Simulation and Virtual Environments for Investigation of Driver Behavior, 149-163.
The operator is required to be constantly vigilant and even more attentive when operating the device. The paper introduces a cooperation of a car simulator realized in the virtual reality (VR) environments and measurements of "human driver behavior" focused mainly on the aspects of HMI and drivers' attention decrease. In the first part a conception and a development of our VR car simulation devices are described. During the development of the car simulators many problems need to be solved. One of these problems is represented by a simplification and a partial automation of a scenery creation. The first part is dedicated to the algorithms used in our tools, which help to automate the creation of virtual scenes. The next part analyses, in greater detail, the tools themselves and the rest of this section deals with demonstration of the scenes, which were modeled using these tools. For simpler and faster generation of virtual sceneries it is suitable to store the models within a hierarchical database 3D object. Our database includes model objects from which it subsequently forms surroundings for the road virtual scenes. In the article is described how to specify the 3D model properties - their fundamental characteristic and consequent differentiation into specific categories. Sound perception cues are one of the most important ones besides the visual cues in the car simulation. The audio section of this article deals with simulating a sound of a car engine as a most significant audio stimulant for the driver. It shows the basics of the cross fading system which renders the car audio from multiple looped samples. The first part contains an analysis of car engine sound, the second part describes how to synthesize it on the computer. Validation measurements and consequent results are shown at the end of this section. The final paragraphs show examples of experiments developed for measurements of the driver's fatigue and other aspects of the driver's behavior.
- [6] Svoboda P., Tatarinov V., Faber J. (Czech Republic): Detection and Early Prediction of Hypnagogium Based on EEG Analysis, 165-174.
Detection and early prediction of hypnagogium based on the EEG analysis is a very promising way how to deal with different states of vigilance. We are dealing with the EEG signal using different methodology mainly based on the spectral analysis such as Fourier transform, autoregressive models and also different kinds of filters. For the detection of hypnagogium we are using methods such as bayes classifier, nearest-neighbor and methods of neural networks. We are performing the analysis of EEG to recognize and classify the hypnagogium.
- [7] Votruba Z., Novák M. (Czech Republic): Complex uncertain interfaces, 175-186.
Both Scientists and System Analytics share common experience that complex interfaces (for example "human - machine" interface within the complex hybrid system, or synapse in the human brain) susceptibly react both to the dimension of the task (i.e.: the number / type of interface parameters / markers) and to the degree of uncertainty.
In order to quantitatively evaluate this effect, the model of interface is presented first. Then the problem is analyzed. The results of the study indicate:
- Even a low degree of uncertainty, "acting" homogeneously on all parameters of the respective interface, has significantly adverse effect on the interface regularity (consequently the reliability of systems processes as well) if the number of parameters (i.e. dimension of the pertinent task) is sufficiently high.
- Even a significant uncertainty in one or in a small number (typically 1 or 2) of interface parameters has a limited or negligible impact on the interface regularity if this interface is sufficiently robust.
- There are three basic attempts how to increase the regularity of complex interfaces: (a) smart simplification (b) utilizing redundancy or contextuality (c) interface conjugation.
1/2005
- [1] Dündar P. (Turkey): Augmented Cubes and Its Connectivity Numbers, 1-8. Deterministic measures of stability are used for some parameters of graphs as connectivity, covering number, independence number and dominating number. For a long time, in the graph theory any vertex is considered with its neighbourhood. By means of this idea, we define the accessible set and the accessibility number of a connected graph. In this paper we search the accessibility number and other parameters of augmented cubes.
- [2] Goltsev A., Húsek D., Frolov A. (Ukraine, Czech Republic, Russia): Assembly Neural Network with Nearest-Neighbor Recognition Algorithm, 9-22. An assembly neural network based on the binary Hebbian rule is suggested for pattern recognition. The network consists of several sub-networks according to the number of classes to be recognized. Each sub-network consists of several neural columns according to the dimensionality of the signal space so that the value of each signal component is encoded by activity of adjacent neurons of the column. A new recognition algorithm is presented which realizes the nearest-neighbor method in the assembly neural network. Computer simulation of the network is performed. The model is tested on a texture segmentation task. The experiments have demonstrated that the network is able to segment reasonably real-world texture images.
- [3] Hrubeš P. (Czech Republic): Recognition of Geographical Information System Layers based on Spatial Analysis, 23-34. Presented in this paper is the idea of GIS layers semantic recognition methodology. The aim was to evaluate a possibility of GIS layer recognition based on spatial analysis and performance tests which validate proposed methodology. The final interest was to develop a GIS layer classifier and evaluate its function for independent data set. In my approach to the classification of the GIS data layers I use methods based on the nearest neighbor and histogram of the distance matrix. The reasons for such a solution are in good complexity of the spatial data description and in implementation of these algorithms under statistics software. In the range of the experiment tests I developed methodology for classification and I verified that it is possible to recognize the spatial layer via spatial statistic. Then I developed the classifier based on the Kohonen's Self Organization Maps and evaluated it on a test set. All the executed tests under artificial spatial data and real GIS data show that the proposed methodology is fully relevant and forms a basis for successful use in practical applications. All executed classification models showed that the proposal methodology could directly recognize the GIS layer, as for layers with similar spatial characteristic they recognize only a class of layers. For complete recognition it is necessary to add other information about layers.
- [4]Ramasubramanian P., Kannan A. (India): Predicting Database Intrusion With an Ensemble of Neural Networks: A Time Series Approach, 35-51. This paper describes a framework for a statistical anomaly prediction system using Quickprop neural network ensemble forecasting model, which predicts unauthorized invasions of users based on previous observations and takes further action before intrusion occurs. This paper investigates a NN ensemble approach to the problem of intrusion prediction and the various architectures are investigated using Quickprop algorithm. This paper focuses on intrusion prediction techniques for preventing intrusions that manifest through anomalous changes in intensity of transactions in a relational database systems at the application level. We present a novel approach to prevent misuse within an information system by gathering and maintaining knowledge of the behavior of the user rather than anticipating attacks by unknown assailants. The experimental study is performed using real data provided by a major Corporate Bank. A comparative evaluation of the two ensemble networks over the individual networks was carried out using a mean absolute percentage error on a prediction data set and a better prediction accuracy has been observed. Furthermore, the performance analysis shows that the model captures well the volatility of the user behavior and has a good forecasting ability.
- [5] Svítek M. (Czech Republic): Theory and Algorithm for Time Series Compression, 53-67. The paper presents new methodology how to find and estimate the main features of time series to achieve the reduction of their components (dimensionality reduction) and so to provide the compression of information contained in it under keeping the selected features invariant. The presented compression algorithm is based on estimation of truncated time series components in such a way that the spectrum functions of both original and truncated time series are sufficiently close together. In the end, the set of examples is shown to demonstrate the algorithm performance and to indicate the applications of the presented methodology.
- [6] Peiyong Zhu, Shixin Sun (China): A Periodic Solution of Delayed Celluar Neural Networks, 69-76.
We mainly prove: Assume that each output function
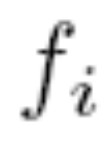 of DCNN is bounded on R and satisfies the Lipschitz condition, if
of DCNN is bounded on R and satisfies the Lipschitz condition, if 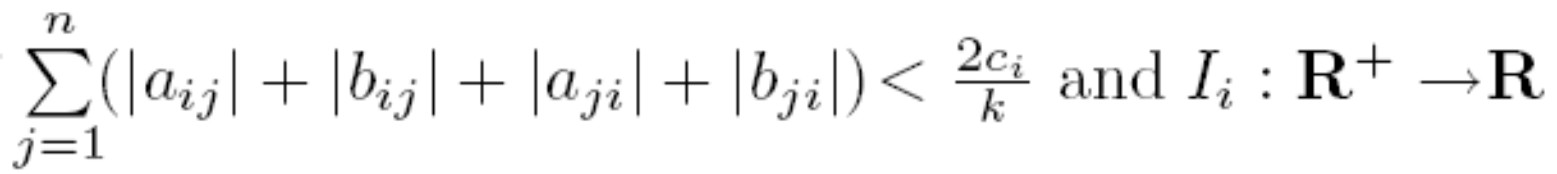 is a periodic function with period ω each i, then DCNN has a unique ω-period solution and all other solutions of DCNN converge exponentially to it, where
is a periodic function with period ω each i, then DCNN has a unique ω-period solution and all other solutions of DCNN converge exponentially to it, where 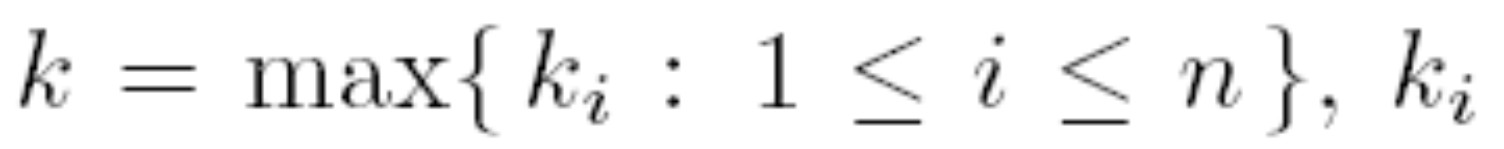 is a Lipschitz constant of for i=1,2,...,n.
is a Lipschitz constant of for i=1,2,...,n.
- [7] Book review, 77-79.
- [8] Book review, 81-84.
Thanks to CodeCogs.com